Recent photorealistic Novel View Synthesis (NVS)
advances have increasingly gained attention. However, these
approaches remain constrained to small indoor scenes. While
optimization-based NVS models have made attempts to address
this, generalizable feed-forward methods—offering significant
advantages—remain underexplored. In this work, we train
PixelNeRF, a feed-forward NVS model, on the large-scale
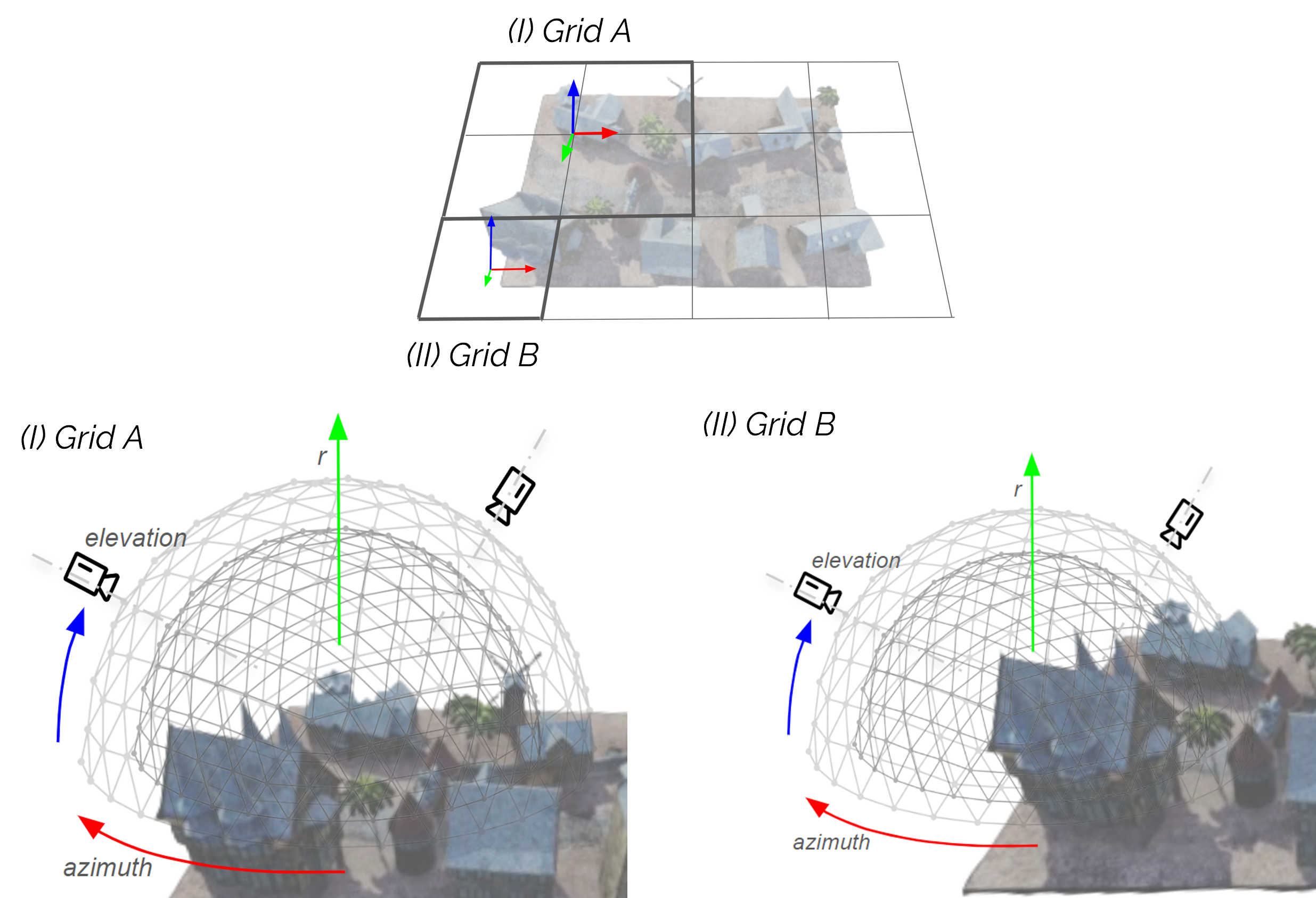
UrbanScene3D dataset. We propose four training strategies to
cluster and train on this dataset, highlighting that performance
is hindered by limited view overlap. To address this, we
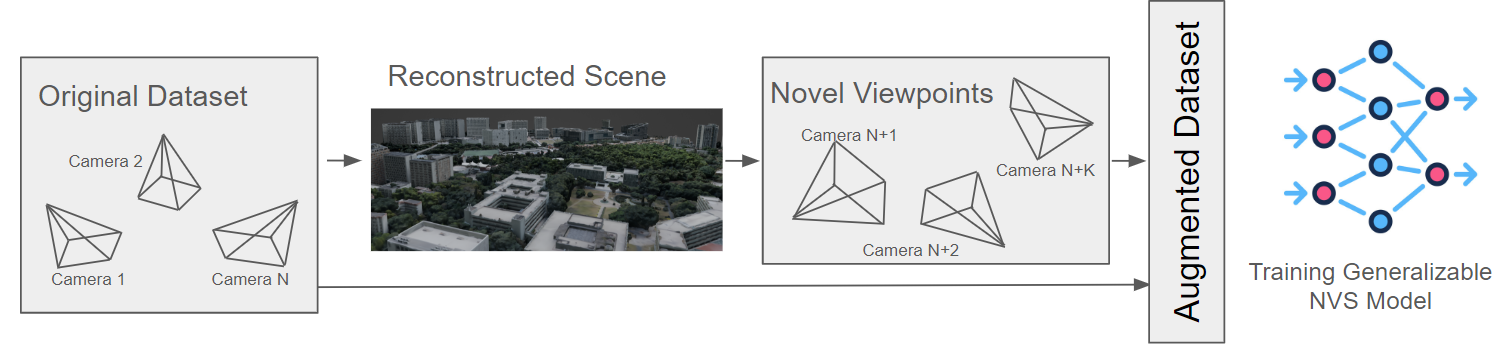
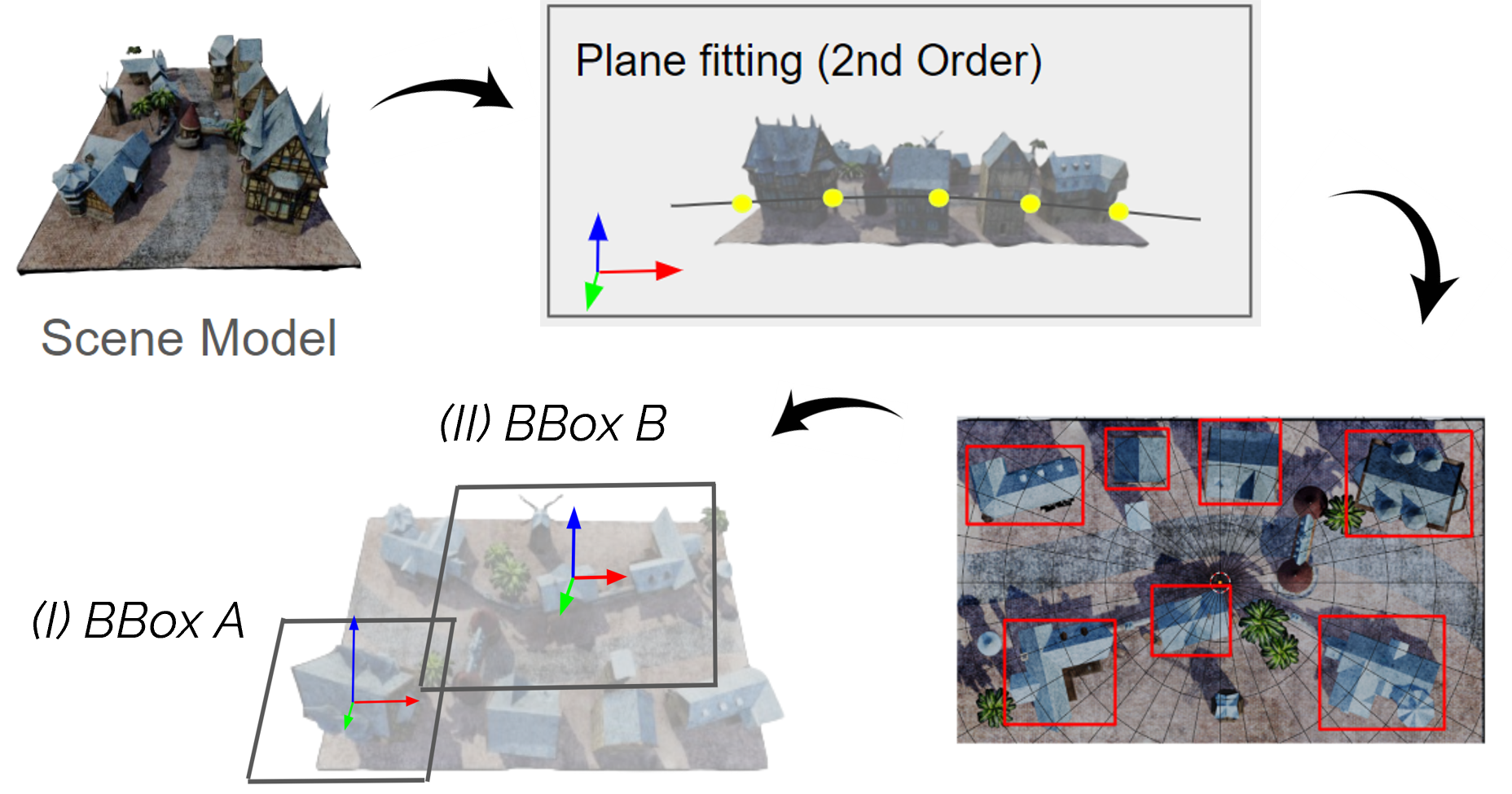
introduce Aug3D, an augmentation technique that leverages
reconstructed scenes using traditional Structure-from-Motion
(SfM). Aug3D generates well-conditioned novel views through
grid and semantic sampling to enhance feed-forward NVS
model learning. Our experiments reveal that reducing the
number of views per cluster from 20 to 10 improves PSNR
by 10%, but the performance remains suboptimal. Aug3D
further addresses this by combining the newly generated novel
views with the original dataset, demonstrating its effective-
ness in improving the model’s ability to predict novel views.